lianxiangbus
- 浏览: 527523 次
-

最新评论
-
Mr.TianShu:
优化一下
public static void te ...
输出101~200内的质数 -
Mr.TianShu:
1既不是质数也不是合数此方法判断0-100就会发生错误错误的写 ...
输出101~200内的质数 -
li_yue_qing12:
求代码啊!!!!
[项目实战] ibatis +spring+struts2+jquery.autocomplete实现产品自动补全功能(一) -
遥远的救世主:
...
多线程编程 高级主题(一)
并查集学习
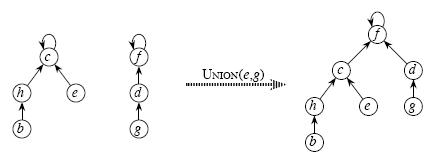
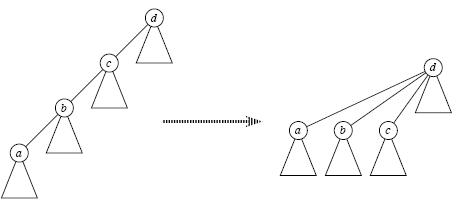









相关推荐
自己学习用的并查集资料,内容还算比较全,适用于初学者
ACM-数据结构-并查集学习
学习并查集的好东东,需要的看看吧,ACM之路
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这一类问题近几年来反复...
有关于并查集的讲解。在此之前根本一窍不通,北大郭炜老师的课件很详细包括课后oj题目练习讲解等,都会使自己的知识点更牢固。
很好的并查集学习资料,这是对先前发布的“并查集初步(C/C++)”的Bug进行初步修改,本版本专门用于教学,若想用于自学,请下载“并查集初步(C/C++)学生版V1.1”,谢谢支持!
并查集,acm,并查集的入门课件,主要使用与ACM学习
学习-并查集的好东西,学习-并查集的好东西,学习-并查集的好东西,学习-并查集的好东西
并查集算法思想 详细讲解并查集的具体细节,学习算法的好东西阿
很好的并查集学习资料,这是对先前发布的“并查集初步(C/C++)”的Bug进行初步修改,本版本专门用于自学,若想用于教学,请下载“并查集初步(C/C++)教学版V1.1”,谢谢支持!
很好的并查集学习资料,包含例题讲解和练习题,经过C/C++语言改写,非常适合你哟!!! 注:本资料有少量bug,若为C++入门,请下载“并查集初步 V1.1 教师版”http://download.csdn.net/source/798595
并查集生成迷宫及A*算法自动寻找路径,学习算法的时候可以借鉴一下,很简单但是很实用。资源为整套源码。欢迎联系交流,共同学习。
并查集资料2021,学习
并查集讲义PPT教案学习.pptx
并查集入门的好资料,供acm初学者学习使用。
并查集及其应用PPT学习教案.pptx
初步学习并查集,了解基本思想,非常适合初学者...........
学习算法的时候可以借鉴一下并查集,很简单但是很实用
c++实现等级类的划分,代码简陋,仅供参考学习。
学习oi的朋友们都知道并查集是一项强大但难懂的知识,要想学习一下可以点击下载哦!~